Update, Oct 2020: we’ve done a lot more since this post! If you want to try working on this problem, Weights and Biases is very kindly hosting a public benchmark.
I’ve just completed an experiment to extract information from TV station political advertising disclosure forms using deep learning. In the process I’ve produced a challenging journalism-relevant dataset for NLP/AI researchers. Original data from ProPublica’s Free The Files project.
The resulting model achieves 90% accuracy extracting total spending from the PDFs in the (held out) test set, which shows that deep learning can generalize surprisingly well to previously unseen form types. I expect it could be made much more accurate through some feature engineering (see below.)
You can find the code and documentation here. Full thanks to my collaborator Nicholas Bardy of Weights & Biases.
Why?
TV stations are required to disclose their sale of political advertising, but there is no requirement that this disclosure is machine readable. Every election, tens of thousands of PDFs are posted to the FCC Public File, available at https://publicfiles.fcc.gov/. All of these contain essentially the same information, but in in hundreds of different formats, like these:


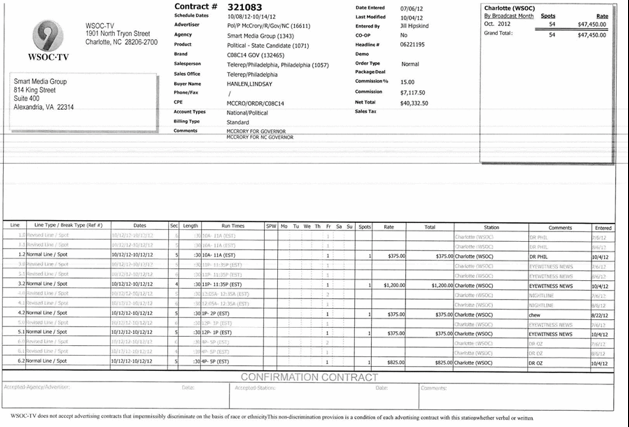
In 2012, ProPublica ran the Free The Files project (you can read how it worked) and hundreds of volunteers hand-entered information for over 17,000 of these forms. That data drove a bunch of campaign finance coverage and is now available from their data store.
Can we replicate this data extraction using modern deep learning techniques? This project aimed to find out, and successfully extracted the easiest of the fields (total amount) at 90% accuracy using a relatively simple network.
How it works
I settled on a relatively simple design, using a fully connected three-layer network trained on 20 token windows of the data. Each token is hashed to an integer mod 500, then converted to 1-hot representation and embedded into 32 dimensions. This embedding is combined with geometry information (bounding box and page number) and also some hand-crafted “hint” features, such as whether the token matches a regular expression for dollar amounts. For details, see the talk.
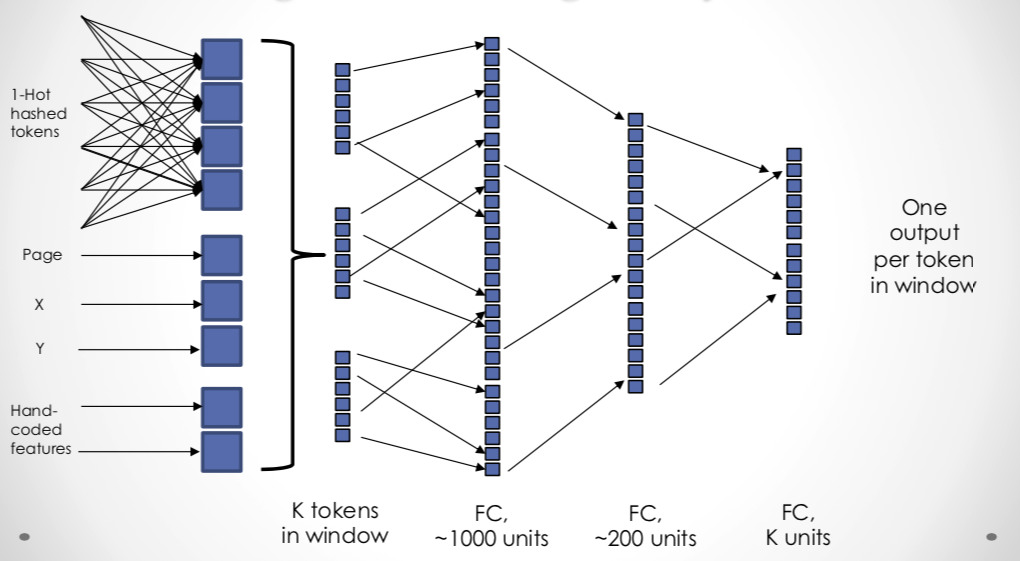
Although 90% is a good result, it’s probably not high enough for production use. However, I believe this approach has lots of room for improvement. The advantage of this type of system is that it can elegantly integrate multiple manual extraction methods — the “hint” features — each of which can be individually crappy. The network actually learns when to trust each method. In ML speak this is “boosting over weak learners.”
A research data set
Are you an AI researcher looking for challenging research problems that are relevant to investigative journalism? Have I got a data set for you!
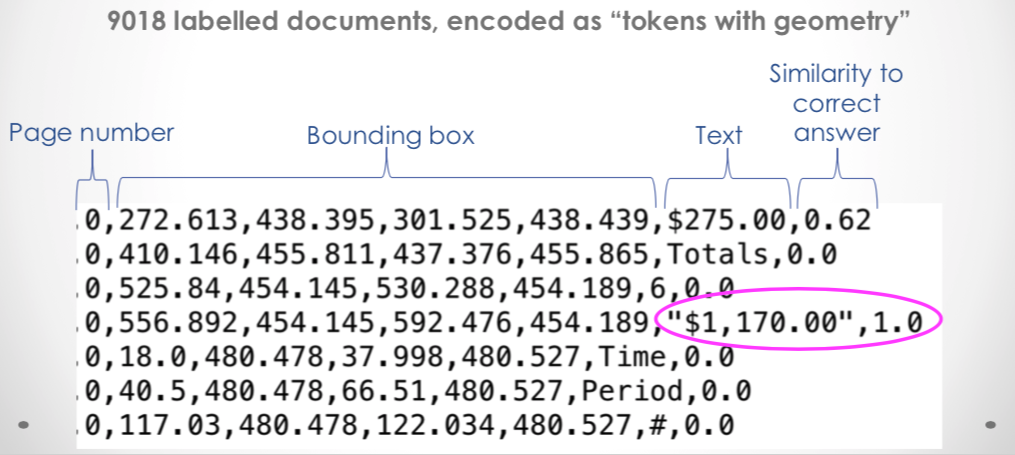
There is a great deal left to do on this extraction project. For example, we still need to try extracting the other fields such as advertiser and TV station call sign. This will probably be harder than totals as it’s harder to identify tokens which “look like” the correct answer.
There is also more data preparation work to do. We discovered that about 30% of the PDFs documents still need OCR, which should increase our training data set from 9k to ~17k documents.
But even in its current form, this is a difficult data set that is very relevant to journalism, and improvements in technique will be immediately useful to campaign finance reporting.
The general problem is known as “knowledge base construction” in the research community, and the current state of the art is achieved by multimodal systems such as Fonduer.
I would love to hear from you! Contact me on twitter or here.
Very useful article. But it seems that you haven’t uploaded “tokenize-pdfs.py” in github.
6oczgu
gjcl25