Folks who want to use AI/ML for good generally think of things like building predictive models, but smart methods for extracting data from forms would do more for journalism, climate science, medicine, democracy etc. than almost any other application. Since March, I’ve been working with a small team on applying deep learning to a gnarly campaign finance dataset that journalists have been struggling with for years. Today we are announcing Deepform, a baseline ML model, training data set, and public benchmark where anyone can submit their solution. I think this type of technology is important, not just for campaign finance reporters but for everyone.
This post has four parts:
- Why form extraction is an important problem
- Why it’s hard
- The start of the art of deep learning for form extraction
- The Deepform model and dataset, our contribution to this problem
Form extraction is incredibly useful
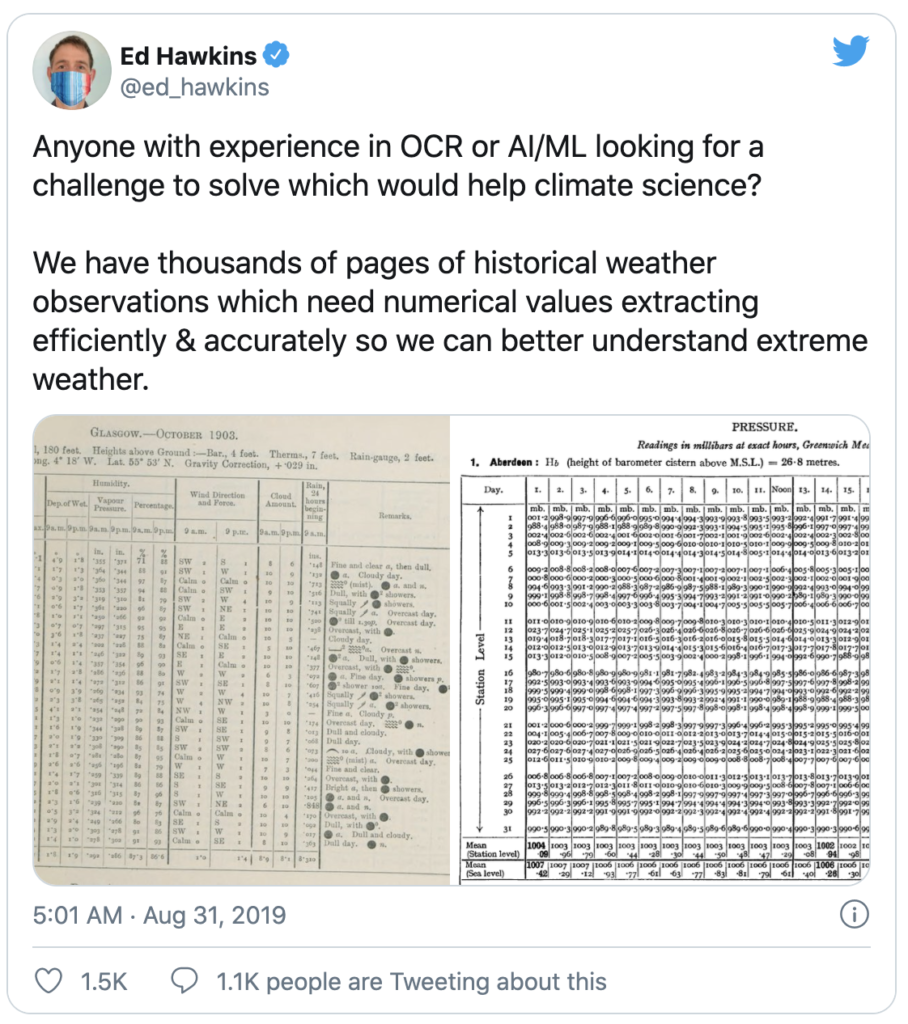
Form extraction could help climate science because a lot of old weather data is locked in forms. These forms come in a crazy variety of different formats from all over the world and across centuries.
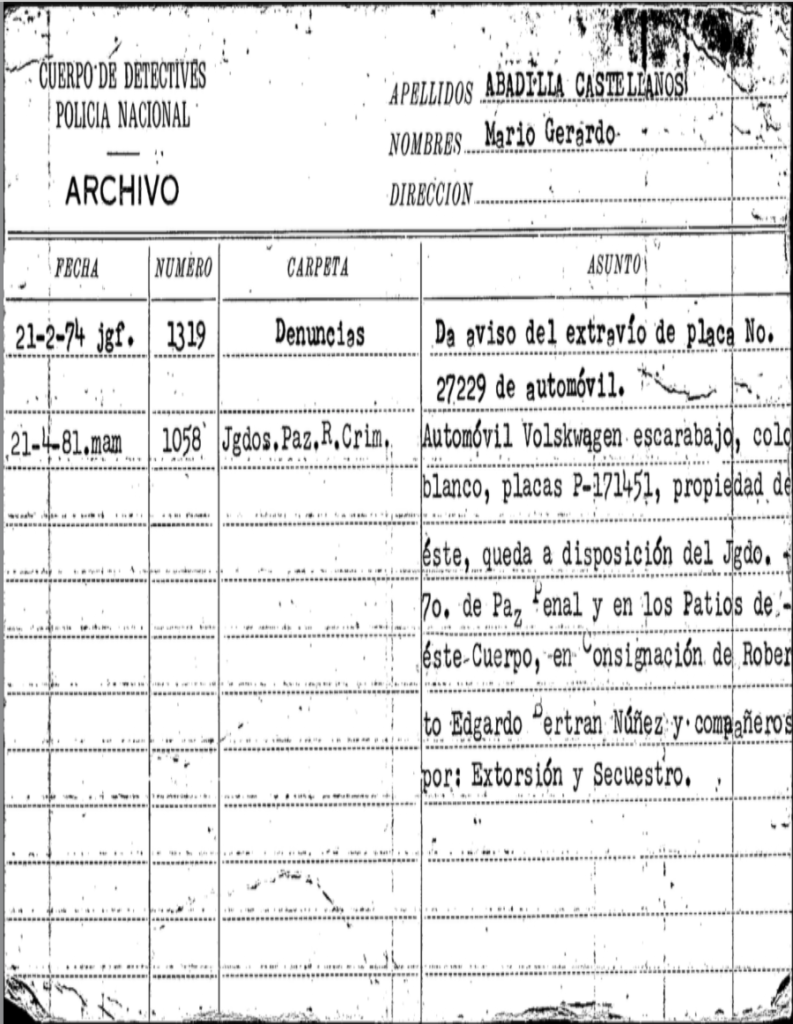
Form extraction is useful for human rights work as well. In 2005, the National Police Historical Archive was discovered in Guatemala, opening up a window to government crimes committed during the 35 year-long civil war. Over 100,000 people were abducted, tortured, or murdered, and in many cases these fragile paper documents are the only record of what happened to someone. They are largely hand-written and come in a wide variety of formats dating back to 1870, some 80 million pages in all.
Form extraction comes up in medicine too, even for present-day documents. UCSF Hospital processes 500 faxed referrals each day, requiring 57 full time staff to type them in. These forms, such as the image below, can look like just about anything. The process has recently been partially automated.

There are plenty of gnarly forms in journalism too. Getting data out of forms can take months on a major investigative journalism project, like the recent FINCEN Files:
In the end, ICIJ and its partners launched a giant data-extraction effort: for more than a year, 85 journalists in 30 countries reviewed and extracted transaction information from assigned suspicious activity reports and manually entered it into Excel files … The effort resulted in 55,000 records of structured data and included details on more than 200,000 transactions flagged by the banks
I believe that this sort of data cleanup work is a far better application of AI to journalism than attempts to automate “finding the story in the data” or that sort of thing. The form extraction problem is well-specified, and data prep takes a lot of time, as I’ve argued at length in Making AI Work for Investigative Journalism.
Why is this hard?
Given that extracting data from paper forms is difficult, expensive, and widely useful you’d think that this would be solved by now. And it sort of is, but not for the kinds of cases above.
Form extraction is so common in journalism that “how do I get this data out of a PDF?” is a FAQ for data journalists. There are a few open-source solutions for table extraction, such as Tabula. There are a number of proprietary form and table extraction products at various levels of complexity, ranging from the straightforward CometDocs to the sophisticated and expensive Monarch. There are also APIs that will turn documents into structured data, such as Amazon’s Textract and the Google Cloud Document API, which has a nice tutorial.
But these products all either require manual interaction to extract data (so they can’t be used on bulk documents) or they use a template to extract data from a single type of form (which necessitates setup work for each type.) They don’t do well when the forms are heterogeneous, even if they all contain the same type of data. Unfortunately, that’s the situation with all the cases above. The problem isn’t extracting data from a form, but extracting data from any form. This is why AI can help: the ability of machine learning models to generalize may make it possible to extract data from previously unseen forms.
This general form extraction problem is so hard that are entire businesses based around it, like Expensify. And we are beginning to see more flexible AI-driven form extraction products that can learn form layouts, such as Rossum.ai. But this sort of technology is proprietary and often specialized to specific types of common business documents. If you need something else, or you need it open source, then it’s time to get to the research.
Generalized Form Extraction: The State of the Art
Here’s what I know about solving the form extraction problem. This section is for developers and researchers who want to try to improve on our benchmark results, or advance the open state of the art.
First, the basics. In many cases, including anything that started on paper, you’ll need OCR to convert images into text. Tesseract 4.0 is near-SOTA OCR in 100+ languages, so you probably want to start there. After you have PDFs with text, you’ll need to convert them into some representation suitable for machine learning. Deepform uses a tokens-plus-geometry format, where the document is transformed into a list of words (tokens) and their positions on the page. We use pdfplumber to do this, an amazing tool which will also do many other useful things (like simple table extraction).
From there, the problem is known as “multimodal form extraction.” A successful model will have to consider not just the text itself but each word’s position on the page, and even information like font size or bolded headings.
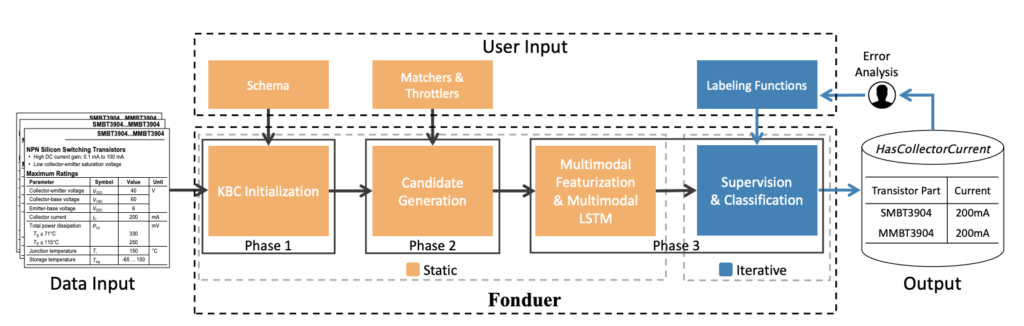
I know of only one open-source multimodal form extraction system that has been used in production. Fonduer, from a team at Stanford, starts from rich document structure including geometry, hierarchy, and fonts, then extracts data using a multi-stage process. First, candidate answers are selected through user-written matching functions. The user can also supply small “labelling” functions which supply extra information that can help choose the right answers. All these functions are small and simple, typically only a line or two of code.

Then, a trained bidirectional-LSTM network uses all this information to choose the correct answers from the candidates.
Just in the last year, several more noteworthy techniques have appeared. This work from several Google researchers starts with tokens and geometry (exactly what PDFPlumber outputs). The process again begins with candidates produced by hand-written matching functions (notice a theme?) followed by a unique classifier. The core idea here is to encode the neighborhood of each token, meaning all tokens within “a zone around the candidate extending all the way to the left of the page and about 10% of the page height above it.” The model also learns a separate embedding of a scalar-valued “field ID” which indicates whether the field is an amount_due, an invoice_id, a due_date, etc. The final layer of the network scores each candidate by computing the cosine similarity of the neighborhood embedding and the field type embedding.
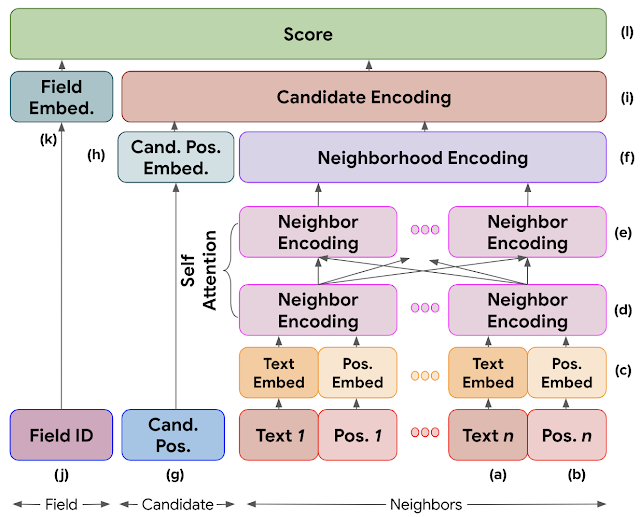
Using cosine similarity between the candidate and neighborhood embeddings forces candidates with similar context to be “near” to each other in embedding space (and this is actually visualized in the paper.) You can think of each learned field type (field ID) embedding as the centroid of the corresponding cluster of similar neighborhoods. Each neighborhood would include, for example, a human-readable field name, so we should expect at least that much similarity in the context of the correct answer for each field type.
There have also been a graph convolutional network approaches to form extraction, as in this helpful tutorial on scanning receipts. The idea here is to encode the geometrical relationship between tokens in the document as edges in a graph, e.g. the nodes representing two tokens get an edge between them if they are horizontally or vertically aligned.
All of these methods so far are strictly supervised, and they’ve all been trained on sets of 10,000-ish documents with all fields labelled. It should be possible to start with a (much larger!) large unlabeled corpus of forms to learn general facts about the structure of documents, much as modern transformer-based language models train on unlabelled text. The (public?) state-of-the-art in multimodal form extraction is LayoutLM, which uses text, geometry, and image embeddings in a BERT model.
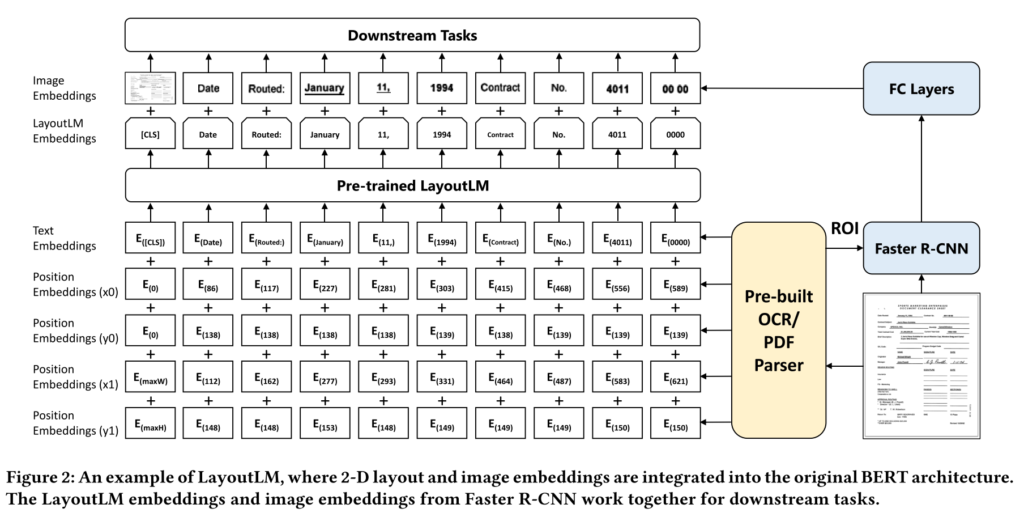
LayoutLM achieves state-of-the-art performance because it can “pre-train” on large unlabelled collections of documents, some of which include millions of forms. It also incorporates image information directly into the multimodal inference, though it’s not clear to me how much this helps relative to just the text, position, and font size/weight.
Deepform: Extracting TV political advertising spending
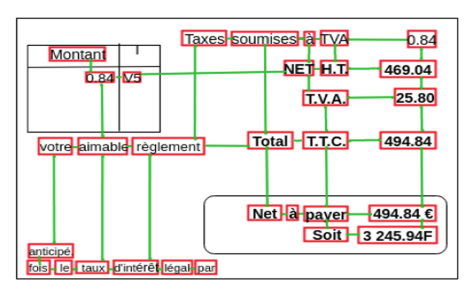
Every election, every TV and cable station is required to disclose the political advertising they sell — but there is no requirement on how they disclose it. These PDFs documents are known as the FCC Public Files, and even though every station is disclosing more or less the same information, different stations use different formats. Hundreds of different formats, maybe thousands.
Searching through these forms for newsworthy items, or analyzing them for broader trends, has been a headache for journalists for many years. Past reporting projects have used massive amounts of crowdsourced volunteer labor (ProPublica, 2012) or hand-coded form layouts (Alex Byrnes, 2014) to produce usable datasets. The option is to buy cleaned data from a political consulting firm for $100k or more, so solving this problem would save journalists tremendous amounts of time or money.
In 2019 I prototyped a deep learning system which could extract one field from the FCC documents with over 90% accuracy, suggesting that it was possible to create a model that could generalize between form types. Today we are announcing Deepform, the result of seven months of work extending this prototype, including:
- A training data set built from 20,000 labelled FCC Public Files documents from the 2012, 2014, and 2020 elections.
- A baseline model to extract five fields from each document: order number, advertiser name, flight dates (from and to), and gross amount.
- A public benchmark, hosted by Weights & Biases, where you can submit your improved model.
- Extracted data for the 2020 election, hosted on Overview.
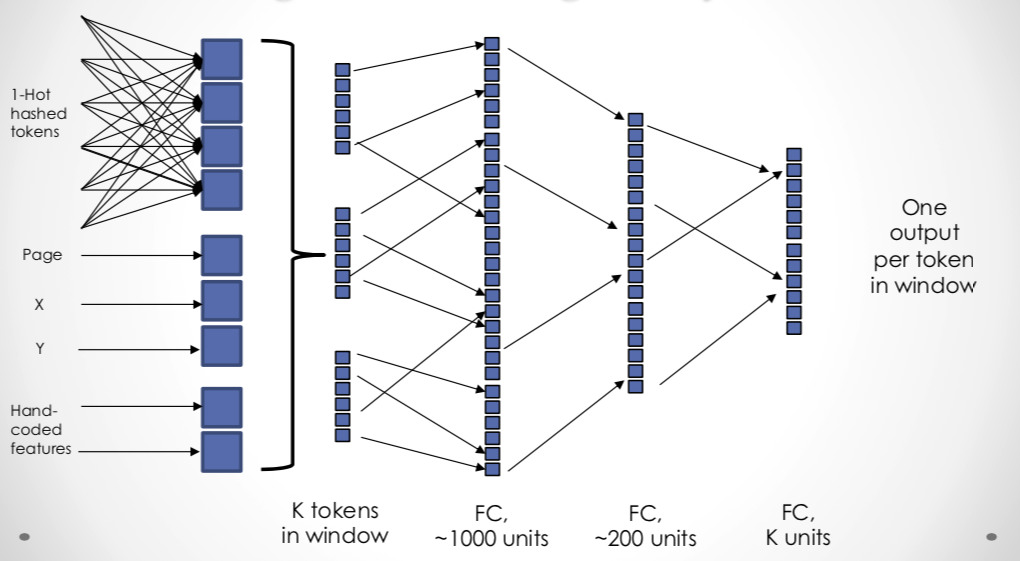
Compared to the research above, our work uses a relatively simple model. We use pdfplumber to extract tokens and their bounding boxes, then a fully-connected network to score each token within a linear window. These windows, perhaps 20-50 tokens wide, are more or less equivalent to the neighborhoods used in other approaches. Like several of the systems above, we also found that including a few hand-built features based on string matching improved performance.
The benchmark scores submissions based on average accuracy across five extracted fields. Right now, our baseline model achieves 70%, but this is a bit misleading: we achieve 90% or more on all fields except advertiser name, where we get 30-40%. This is because advertiser name is the only field where the answer spans multiple tokens, so we often get only part of the name, even if it’s still human recognizable. Actually, most of the models above are not designed to handle multiple token answers either.
The actual extracted data for 2020 available on Overview. You can search, view the original documents and metadata, annotate and download nearly 100,000 invoices and orders from the FCC Public File for the 2020 election. Create an account and choose “copy an example document set,” then clone the fcc-data-2020 document set.
This data is a little late to be useful to reporters covering the 2020 election. Rather, the significance of Deepform is that it’s public progress on a difficult and important AI problem. But we have much further to go. If you are an ML engineer who would like to get involved in form-extraction-for-democracy, I’d encourage you to try your hand at the public benchmark, very kindly hosted by Weights & Biases. We’ve done all the hard work of building the data set and a baseline model — any of the methods discussed above might be quite likely to beat our work.
Finally, a big shoutout to the Deepform team: Gray Davidson, Daniel Fennelly. Andrea Lowe, Hugh Wimberly, and Stacey Svetlichnaya. None of this would have been possible without your dedication over the last seven months.
Hey Jonathan,
I recently went through your github repo of DeepForm and I was trying to build it around my use case. I would be highly obliged if you could help me out in understanding and implementing it around deepform.
Great share, I have read it thanks for providing such an amazing blog. Valueappz
Hello, I’m Mr. Jerry.
I read through your website and found your writing to be enjoyable. I read a few of the blogs on your website and found them to be helpful for my field of work.
I sincerely appreciate the awareness that your website’s insightful content is generating. I would be very interested in contributing a guest post to it. I’m not here to squander your time away. Instead, I have some fresh post ideas that would be a hit with your visitors and a wonderful addition to your site.
I’m getting in touch with you to provide your blog a fantastic content. Do I still have time to create some useful and practical content?
I’m forward to hearing from you again.
Regards and thanks
Bonjour,
l’IA nous aide beaucoup dans notre travail, c’est un outil précieux. Nous avons constaté que ChatGPT cherche actuellement a fournir le moins d’effort. Sur notre site (le blog), nous avons généré les images à l’aide de Prompt dans Midjourney, c’est bien mais c’est coûteux : https://www.innovayogameditation.com/
Avant l’IA, un tel travail aurait été difficile à réaliser.
Pouvez-vous nous faire une présentation des différentes alternatives.
Merci pour le contenu
Sohbet Hatti: Anonim Sohbet, Gerçek Bağlantılar. Sohbet Hatti
Sohbet