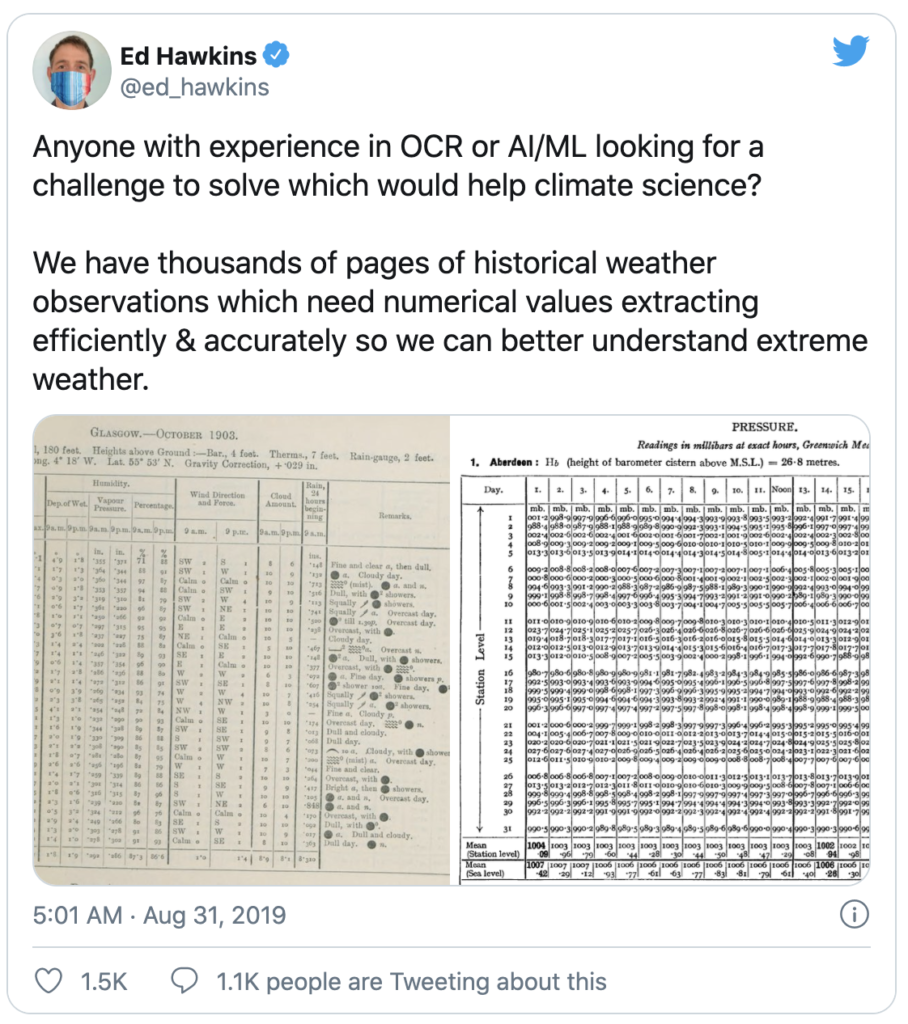
Folks who want to use AI/ML for good generally think of things like building predictive models, but smart methods for extracting data from forms would do more for journalism, climate science, medicine, democracy etc. than almost any other application. Since March, I’ve been working with a small team on applying deep learning to a gnarly campaign finance dataset that journalists have been struggling with for years. Today we are announcing Deepform, a baseline ML model, training data set, and public benchmark where anyone can submit their solution. I think this type of technology is important, not just for campaign finance reporters but for everyone.
This post has four parts:
- Why form extraction is an important problem
- Why it’s hard
- The start of the art of deep learning for form extraction
- The Deepform model and dataset, our contribution to this problem
Form extraction is incredibly useful
Form extraction could help climate science because a lot of old weather data is locked in forms. These forms come in a crazy variety of different formats from all over the world and across centuries.